篇首语:本文由编程笔记#小编为大家整理,主要介绍了开源机器学习软件对AI的发展意味着什么?相关的知识,希望对你有一定的参考价值。

作者| Max Langenkamp
OneFlow编译
翻译|徐佳渝、杨婷
为什么要关注机器学习开源软件(MLOSS)?在我们看来,MLOSS对AI发展来说举足轻重,但未获重视。
机器学习开源软件是开源许可下发布的专为机器学习而设计的计算机软件。机器学习开源软件包括框架(如PyTorch和Pyro)、“一体化”软件包(如scikit-learn)以及模型开发工具(如TensorBoard),但不包括Jupyter Notebook这类交互式计算工具。虽然Jupyter Notebook并非专为机器学习而设计,但是相关从业者经常会用到这款工具。
1
机器学习开源软件举足轻重,但未获重视
MLOSS举足轻重
过去十年,只要构建过ML模型的人都知道MLOSS至关重要,无论是Deepmind的研发工程师,还是印度的高中生都无一例外会使用开源软件来构建模型。我们采访了24名ML从业者,他们都给出了相同的答案:MLOSS工具在模型构建中的地位举足轻重。
从业者都在免费使用MLOSS工具,也就意味着这类工具会对人工智能发展产生巨大影响。然而,探索MLOSS对AI发展影响的研究人员却寥寥无几。
MLOSS未获重视
迄今为止,研究者就影响人工智能发展的因素展开了多次讨论,其焦点都集中于算力,部分研究者将算法和数据也列为了影响因素之一。例如,艾伦·达福(Allan Dafoe)认为影响人工智能发展的关键因素是计算能力(算力)、人才、数据、洞察力及资金。[1] 黄(Hwang) (2018)探究了硬件供应链对机器学习发展的影响。罗森菲尔德(Rosenfeld) (2019)和海斯特内斯(hesistest)(2017)研究了数据集大小与人工智能模型精度的关系。
越来越多的文献都提到了数据集大小和人工智能模型精度,旨在明确如何建立人工智能中输入和预测误差之间的关系模型。然而,据我们所知,目前还未有关于MLOSS如何影响人工智能发展的深入研究。
目前,我们的关注点是数据、算力等因素如何改变人工智能的发展方向,不过,同时也应聚焦于MLOSS在人工智能发展中的角色。
MLOSS及AI生产函数
我们在早期研究中存在这样的疑惑:数据、算力及MLOSS这些AI生产的影响因素相互之间有何联系,而阐明这些因素之间的联系正是理解AI系统开发默认轨迹(default trajectory)的关键。
柯布-道格拉斯生产函数(Cobb-Douglas production function)是经济学中常用的界定方式。该函数用于资本和原材料等变量的建模,通过函数参数化以表示投入与产出的关系。
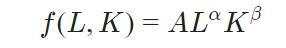
CD生产函数的表示形式
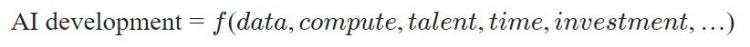
AI生产函数的隐含形式
艾伦·达福将“AI生产函数”应用于人工智能治理,并提出构成该生产函数的关键在于算力、人才、数据、投资、时间以及先前进展和成果等指标[1]。达福就“人工智能进展”研究进行了探讨,此外,在类似研究中也有相关探讨,以解除人工智能特定范式的思维限制。
实际上,这就相当于“深度学习”和“人工智能”。而我们可以选择不同范式,不过认识到这些范式功能的多样性也十分重要。例如,概率程序更容易吸收现存的显性知识,同时能减少对大数据集可用性的依赖。
虽然生产函数可以明确区分出影响深度学习发展的因子,但也存在局限性。特别是当生产函数被认为是自变量的乘积时,不会考虑生产因子之间的共同依赖关系,而且可能还会隐藏每个因子的上下文信息。
还有另一种方法可以阐明影响AI生产的因子,即使用有序的功能依赖图,亦称沃德利地图(Wardley map),来解释因子之间的共享依赖关系。例如:中间模型表示依赖于算力基础设施和MLOSS框架。
2
沃德利地图为AI生产函数提供了最佳替代方案
沃德利地图应用广泛。譬如,可在无手机的情况下用于求生,也可用于电车的路况预测。此外,还有本关于沃德利地图理论的书籍。为探寻MLOSS在AI生态系统中发挥的作用,我们在下文提供了简单示例。
构建沃德利地图的三大主要步骤:描述用例、为处理用例所需的技术功能下定义以及对该地图相应功能进行排序。
以下是“构建深度学习模型”的用例,也是重中之重。我们将重点关注框架、预训练模型、数据及硬件的主要功能,且各功能之间相互具有依赖性。如,框架编译软件(Glow编译器)受到ML框架(PyTorch)的影响,而框架编译软件依赖于中间表示(ONNX),此外,中间表示又会受到硬件(NVIDIA GPU)的影响。
现阶段,我们旨在阐明与ML框架(MLOSS为典型示例)相关的某些关键功能,而非对各方面都泛泛而谈。
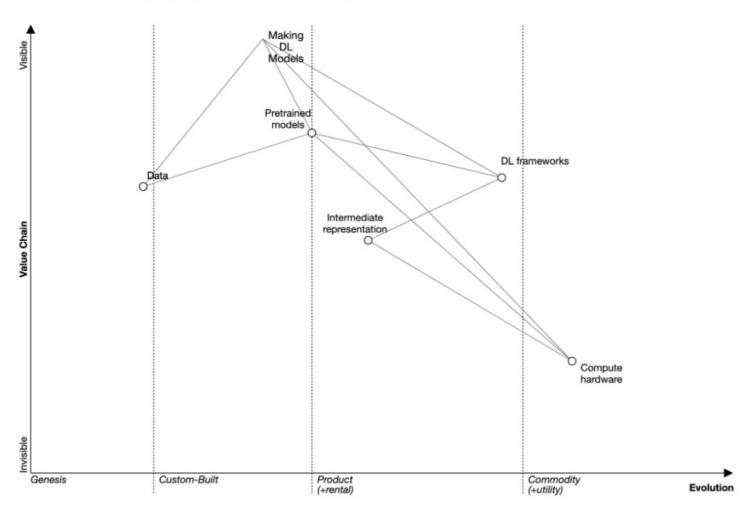
图1. 以沃德利地图构建深度学习模型
通过沃德利地图,我们能更清晰阐述有关塑造深度学习研究的能力之间的关系。基于此,推断出哪些功能将成为未来焦点。我们会在最后一节详细讨论“MLOSS之未来”。
稍后,我们将通过沃德利地图来探讨人工智能的未来。
3
MLOSS通过构建标准、推行实验及创建社区来促进人工智能研究的发展
我们对23名参与者进行了定性访谈,进而确定了MLOSS影响人工智能生态系统的三大主要因素。
构建标准
标准化是指我们普遍认可的单一技术或技能规范。参与者从研制标准化模型类型、协调框架、为开发人员提供一致的用户体验这三个方面谈论了构建标准带来的的影响。
对大型神经网络相关从业者而言,模型类型标准化做出的贡献最为突出。十年前,拥有百万参数的模型是一项浩瀚工程。然而现如今,研究人员只需连接互联网以及使用合适的硬件,就能免费下载一个超1700多亿参数的模型或用这一模型进行在线推理。因此,如今大多数与机器学习相关的工作都会涉及大型神经网络,这与MLOSS工具的普及以及硬件和性能工程的发展密不可分。
我们见证了深度学习框架的高度标准化:虽然2016年MXNet、Theano、TensorFlow、Caffe2、Torch这几种深度学习框架占据很大的市场份额,但是西方相关从业者已普遍将PyTorch、JAX及TensorFlow视为深度学习的三大主流框架。
该访谈中,所有参与者至少使用过这三大主流框架中的一种。据Paperswithcode显示 ,截至2022年6月,采用PyTorch的相关论文占公开发表论文的62%、JAX占7%,TensorFlow占1%。虽然DeepMind公开支持JAX这类框架的使用,但是,我们认为Paperswithcode关于JAX的使用数据无法证明JAX越来越受欢迎。
此外,我们还可以看到框架内部用户体验层面的融合。部分参与者指出,TensorFlow以往默认的基于graph的机制无法给予人们直观感受,对初学者而言更不友好。他们解释道:因为PyTorch具有更为直观的命令式模型规范,所以才采用PyTorch。
值得注意的是,由于受到PyTorch带来的冲击,TensorFlow 2.0也采用了PyTorch的接口,使其用户体验与PyTorch趋于一致。
推行实验
推行实验不仅能迅速落实我们的想法,还能提供新的思考方式。PyTorch Lightning开发了一个权重矩阵汇总模块,从而节省了研究人员调试模型的时间。而Torch的命令式编程也为研究人员提供了新思路。这也意味着将基于graph的模型规范应用于Tree-LSTMs这类新颖架构成为现实,这在以前是无法想象的。
创建社区
与开源软件(OSS)生态系统类似,MLOSS的重要之处在于它为社区技术贡献者及用户提供了交互机会。创建这类社区的好处诸多,例如用户能为社区贡献力量、提供反馈、输出技术内容,并为MLOSS志愿者提供就业机会。
开源软件论坛为交流提供了新平台,让用户成为社区贡献者是很好的实例。社区中也发生了一些趣事,一些对社区作出了巨大贡献的用户随后被社区项目赞助者看中,从而获得了工作机会。虽未经系统统计,但总的来说加入MLOSS论坛及社区就有可能获得一定的就业机会。
通过在线社区,人们可采取多种方式与项目组织方进行交流。例如,PyTorch的联合创始人Sousmith Chintala曾公开谈论PyTorch社区对早期工具开发所带来的影响。要想开源软件研发走得更远、保证项目的成功,关键在于能否获得大众认可;而要想对项目作出一个不被支持的修改,可谓难上加难,即使失败也不足为奇。为了让这一观点更具说服力,不妨邀读者来一探究竟:Facebook更改React项目的开源许可协议为何会失败。
4
经济激励措施、社会技术因素和意识形态共同决定MLOSS的发展
激励措施

图2. 有关商业激励措施如何影响MLOSS的建议
结合案例研究及参与者的建议,我们发现大公司和初创公司的商业激励措施各不相同。大公司资助MLOSS是为了引进研发人才,从而能间接控制开源软件生态系统,强化现有能力。
由于许多开源工具的研发人员以前是用户,他们很难清晰表达如何间接控制开源软件生态系统,因此引进人才不足为奇。这些在如何设置默认值(如:PyTorch兼容什么类型的硬件)或如何拓展项目发展方向(如:HuggingFace是否优先考虑与Graphcore的IPU或Google的TPU的兼容性)上均有体现。
最后,无论增加计算需求(对数字云提供商更有益)还是改进现有堆栈方式,增加MLOSS的使用往往能提升现有功能价值。由于TensorFlow的广泛使用,谷歌Colab的用户量也大大提升。而共享PyTorch更是明显改善了Facebook/Meta的人脸识别、图像字幕功能。
初创公司为社区提供MLOSS以改进现有产品,助力未来产品。社区不仅仅是社区,更是强大的护城河。它可以助力发挥文化影响力、改善产品、获取营利途径并赋予人们集体认同感。
Hugging Face提供的大型语言模型包广受欢迎便是一个很好的例证。Hugging Face开源了强大、可访问的语言模型包,此举让社区收获了大量粉丝。2022年,该公司通过实施有偿模型训练或模型推理,并为大企业提供咨询服务才实现了现金流回正。社区可以帮助公司发掘人才、改善现有产品、挖掘企业服务的消费群体。
社会技术因素
除了资金和意识形态之外,还有很多社会技术因素也对MLOSS有明显影响。以下是三个最为突出的影响因素。
1. 软件易用性是制胜关键
软件的功能会极大地左右人们的选择,人们倾向于选择用户界面最直观的软件。值得一提的是,尽管最初缺乏对生产系统命令式方法的支持,TensorFlow最终还是采用了PyTorch的命令式神经网络规范。TensorFlow基于graph机制与PyTorch基于eager的机制之间的竞争就好比是Lisp语言和C语言,或者“正确的事情”与“越坏就越好”之争。
与Lisp语言相比,C语言简单且完整度不够,但是这种“更糟”的C编程语言的采纳率却远远超过了复杂、完整且“正确”的Lisp语言,PyTorch和TensorFlow之间的竞争也是如此,PyTorch这种更为简单的方法战胜了TensorFlow更高效的基于graph的模型。
2. 部分代码实现标准化
数据集操作(dataset manipulation)和矩阵微分(matrix differentiation)是机器学习的两个常见任务,我们就以此为例。数据集操作在数据集之间的差异很大,但需要的步骤很少。相比之下,矩阵微分在模型之间非常相似,但需要的步骤更多。矩阵微分的单调乏味和相似性意味着它是软件中最先实现标准化的任务之一。一般来说,模块化、同质化和琐碎的任务会最先被标准化。
3. 研究社区的兴趣
机器学习中的流行范式对MLOSS有显著影响。目前,机器学习的主要模型类型是深度学习,这推动了深度学习(与替代概率编程(alternate probabilistic programming)或自动规划(automated planning)等机器学习范例相反)MLOSS工具的发展。
当然,机器学习主流范式本身就会受到多种因素的影响,硬件状态、权威基准、商业适用性对于塑造机器学习主导方法来说都很重要。想要深入了解相关信息,大家可以参阅Dotan和Milli (2019)2的论文。
意识形态
最后,意识形态对于MLOSS的发展也有着至关重要的影响。大多数MLOSS关键人物都受到特定世界观的影响,他们的世界观可能带有宗教性质或是个人价值观的产物。这些价值观激励着研究人员去改善其他开发人员的体验或是促进AI的发展。
Travis Oliphant是NumPy(Python中最常用的库之一)的创建者,他讲述了创建NumPy作为公共服务时发生的故事,然而在那时,他的这一想法遭到了杨百翰大学(Brigham Young University)的顾问和同行们的反对。
其他研究人员单纯认为推动AI的发展能带来很多好处。Soumith Chintala在一次博客访谈中被问及Facebook赞助PyTorch的原因,他答道,“在AI研究院(Facebook AI Research)中我们有一个单点议程,这个议程是为了解决AI方面的问题,包括授权他人去解决相关问题。
这似乎意味着“解决AI”将极大促进社会发展,这种发展可以是发明新的药品也可以是证明新的定理。同样,H2O.ai和Hugging Face都将“人工智能民主化”作为开源其产品的核心动机。
5
MLOSS(深度学习)中的自我强化反馈循环
在本节中,我们将讨论MLOSS的增殖(proliferation)方式,这种方式可能会选择性地偏爱某一种机器学习(深度学习)类型。
AI深度学习范式的替代方案
除了深度学习,AI研究还有其他范式,比如概率机器学习(probabilistic machine learning)、基于规则的专家系统(rule-based expert systems)以及自动规划(automated planning)。
正如一些受访者所说,尽管深度学习是 ML/AL 研究中的主导范式,但我们很难理清深度学习取得进步的原因,显然技术优势是一部分原因,但是随着 MLOSS 生态系统的进步,我们也不能忽视进步背后巨大的工程优势。充其量,很难评估若替代方法具有类似资源,技术会如何进步。在最坏的情况下,深度学习创造了一种自我强化动力,使得生态系统的影响比底层技术的优势更重要。
提到深度学习没有明显优势的领域,验证飞行软件(verifying flight software)就是一个例子,它对确定性有很高的要求。在这些领域,工程师们会选择使用与自动规划密切相关的定理证明器(theorem provers)来正式验证软件质量。目前深度学习还不能胜任这方面的任务,因为它们无法提供正式的保证。
更好地支持深度学习工具有助于加强深度学习
目前MLOSS工具有两种支持深度学习的方式:减少开发人员摩擦和改变研究人员激励措施。
PyTorch和FastDownward分别是深度学习和自动规划领域最流行的两个开源工具。PyTorch主要由Facebook的AI研究院开发,并得到了极好的支持。用户通常可以通过单个搜索引擎查询来解决技术问题,这个查询会解析数以万计的帖子和活跃用户。许多有用的代码片段详细说明了如何调试尺寸不匹配的张量。
现在我们来聊一聊FastDownward。FastDownward的安装非常重要,需要操作系统的基本知识才能下载压缩文件包 (tarball) 并手动配置安装。如果遇到技术问题,用户很难立即获得支持。在我们尝试的大多数错误查询中,通过搜索引擎直接搜索的方式找不到答案,所以我们不得不求助于他们的自定义论坛。我们这样说并不是在贬低FastDownward,而是想要说明全职工程师团队之间在用户体验上的巨大差异。
在采访过程中,我们看到了工具使用摩擦的微小差异是如何推动TensorFlow转向PyTorch的。我们认为,研究工具的易用性对研究人员关注问题的选择有着显著的影响。通过这种方式,当前最流行的MLOSS工具(PyTorch、JAX、Hugging Face等)促进了深度学习方面的工作,这并不是深度学习作为AI范式的科学价值的直接结果。
因为强大的生态系统支持,深度学习工具已经生产化,这让深度学习工程成为一种非常理想的技能组合,这是MLOSS加强深度学习的另一种方式。
深度学习工具易用、可靠且得到大量用户社区的支持,因此许多公司都可以使用深度学习。很多公司已经开始通过TensorFlow等工具应用深度学习,因此,相比其他范式,深度学习领域专家拥有更多的工作机会,同时行业里对涉及深度学习工作的需求量也更高。在Indeed.com上有超过15000个岗位涉及深度学习,而涉及概率编程和自动规划的岗位则分别只有40个和8个。
6
MLOSS的未来
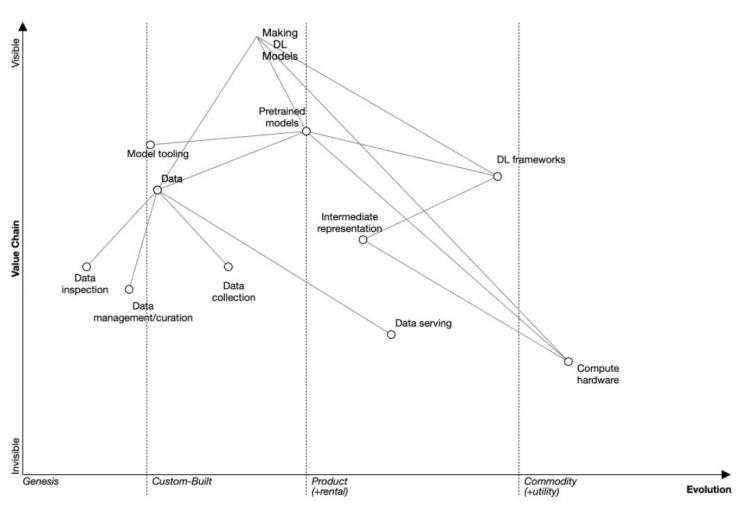
图3: 深度学习模型的扩展沃德利地图
前面提到过的沃德利地图可以对技术发展轨迹作出一些预测。一般来说,能力越靠近左边就意味着该能力越是不足,就越会制约技术的发展,生态系统的注意力就会转向去提升这些相对被忽视的能力。与定性证据相结合,沃德利地图推测出了下面四个发展趋势。
趋势1:MLOSS的重心将从深度学习框架转移
尽管深度学习框架(PyTorch 、TensorFlow、Chainer、Theano、Torch以及华为最近发布的MindSpore)之间的竞争非常激烈,但使用框架表达深度学习模型已不再是瓶颈。
PyTorch的创建者之一Soumith Chintala隐晦地说道“通过PyTorch和TensorFlow,我们已经看到了框架之间的融合趋势,接下来竞争的主战场将会是框架编译器,比如XLA、TVM以及PyTorch的Glow,这一领域将会迎来大量创新”。
趋势2:更多大型预训练模型工具
最近,许多著名项目都在对大型预训练模型进行迭代升级。Github的大模型Copilot是GPT-3[12]的微调版本,旨在协助Python进行代码编写。从最基础的层面来说,这涉及为预训练模型提供服务的基础设施。
当前的大语言模型太大,无法在单台计算机上运行,但OpenAI的GPT-3 API和Hugging Face的服务基础设施已经能够做到这一点。后续工具允许管理不同模型版本,用于组合大型的不同预训练模型的元框架,以及用于将不同模式(例如视觉、声音、文本)合并到预训练模型中的工具。
趋势3:(潜在闭源)数据工具更加多样
许多初创公司正试图解决当前处理数据的临时性质(ad-hoc nature),但尚未整合到单一工具上。更广泛地说,随着 Andrew Ng 的“以数据为中心的人工智能”等活动的发展,许多研究人员认为数据这一工具和研究的重点被忽视了。如果这一看法正确,那么用于数据检查和生产的工具将变得尤为重要。
是否对这些未来工具开源将取决于任务规模。与大学或小型初创公司的 GB 级实验相比,PB 级数据系统,例如特斯拉的自动驾驶汽车数据pipeline会开源的可能性要小得多。这可能会让大小型工具发展道路进一步分化,大规模工具由 Scale 等专有平台提供,部分小规模数据工具则会开源,可供研究人员免费使用。

表1.不同类型的数据工具
对风险的简要反思
数据工具的发展趋势对机器学习的中期风险来说意味着什么?与计算的发展趋势类似,数据工具的发展趋势似乎也是小部分公司集中了大部分能力。这种发展趋势可能更便于管理,各国政府都已成功展现出管理由通用技术发展而来的垄断行业的能力,比如说电力。然而令人担忧的是,我们对这些技术的控制能力远远跟不上管理能力的发展。
MLOSS 中的社区规范也对潜在风险有重大影响。因为MLOSS有很多强大社区,如果其中某个有影响力的社区无视发布强大AI系统的安全问题,在这种情况下,我们认为高风险模型(例如致命病毒生成)的研究人员更可能公开发布他们的模型。
因为AI系统通常是可组合的,所以我们预测模型增殖(model proliferation)的风险可能呈非线性增长。由于不良分子可以将不同模式的模型相结合,因此公开可用模型可能产生的风险将远远超出公开的模型数量。如果要严肃对待这种情况,那么我们就必须要在模型发布之前制定谨慎的相关规范。
为了增加研究可靠性,我们对模型未来的发展前景作了一些推测,这些推测都有一定的可能性:
截至2027年1月,根据Paperswithcode(中国境外),PyTorch和JAX将成为最受欢迎的三大深度学习框架中的其中两大框架。
Python将成为2027年最流行的机器学习语言。
ONNX将成为主流的中间表示框架。
在2023至2027年间,对公众闭源的前5大语言模型不会开源。
截至2027年,三个最受欢迎的数据工具提供平台在很大程度上会是专有的,也就是说他们不会开源堆栈的关键组成部分。
这些预测大多基于我们的直觉,并不完全准确,但我们认为,无论如何这些粗略的预测都有一定的作用,因此也将其列了下来。
下一步研究方向
其他领域(比如LLVM等编译器)里的MLOSS和OSS有哪些相同/不同点?
我们期望数据工具以何种有别于框架工具的方式发展?
扩展概率编程与深度学习(特别是计算)所需的能力有何不同?
中国的MLOSS与美国的有何不同?这对人工智能研究知识的传播来说意味着什么?
开源数据工具的激励与其他MLOSS(尤其是框架)的激励有何不同?
(本文经授权后由OneFlow社区编译发布,译文转载请联系获得授权。原文:https://maxlangenkamp.me/posts/mloss_essay/)
其他人都在看
OneFlow v0.9.0正式发布
OpenAI掌门人Sam Altman的成功学
李白:你的模型权重很不错,可惜被我没收了
比快更快,开源Stable Diffusion刷新作图速度
OneEmbedding:单卡训练TB级推荐模型不是梦
GLM训练加速:性能最高提升3倍,显存节省1/3
“一键”模型迁移,多语言AltDiffusion推理性能翻倍






 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有